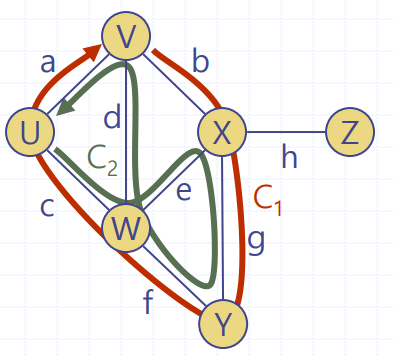
👉가중그래프와 두 개의 정점 u와 v가 주어졌을 때, u와 v사이의 무게의 합이 최소인 경로를 구하는 문제
최단경로길이 : 간선들의 무게 합
응용분야
👉 인터넷 패킷 라우팅, 항공편 예약, 자동차 네비게이션 등등
📢 최단경로 속성
속성 1
👉 최단경로 부분경로(Subpath)역시 최단경로이다.
속성 2
👉 출발정점으로부터 다른 모든 정점에 이르는 최단경로들의 트리가 존재한다. = 단일점 최단경로(Single-Source Shortest Paths)
최단경로는 최소신장트리와 달리
👉 무방향뿐만 아니라 방향그래프에도 정의된다. 👉 그래프에 음의 무게를 가진 싸이클이 있거나, 무방향그래프에 음의 무게를 가진 간선이 있으면 부정한다. 👉 최단경로트리(Shortest Path Tree)는 루트트리
가중 방향그래프에 음의 무게를 가진 싸이클이 존재
👉 최단경로는 존재하지 X
가중 무방향그래프에 음의 무게를 가진 간선이 존재
👉 최단경로는 존재하지 않는다.
최단경로 알고리즘
그래프
알고리즘
시간
음이 없는 무게를 가진 간선이 없는 그래프
Dijkstra(다익스트라)
O(Mlog(N)) or O(N^2)
음의 무게를 가진 간선이 있는 방향그래프
Bellman-Ford(벨만-포드)(BFS에 속함)
O(NM)
비가중그래프
BFS
O(N + M)
DAG ( 방향 비싸이클 그래프)
Topological Ordering(위상정렬)
O(N + M)
📢 Dijkstra 알고리즘
정점 s로부터 정점 v의 거리 : s와 v사이의 최단경로의 길이
Dijkstra 알고리즘은 출발정점 s로부터 다른 모든 정점까지의 거리를 계산한다.
전제
👉 그래프가 연결되있다. 👉 간선들은 무방향이다. 👉 간선의 무게는 음수가 아니다.
정점 s로부터 시작하여 정점들을 차례로 배낭에 넣다가 결국엔 모든 정점을 배낭에 넣는다.
각 정점 v에 거리 라벨 d(v)를 저장하여 배낭과 인접 정점들을 구성하는 부그래프에서 s로부터 v까지의 거리를 표현
반복의 각 회전에선
👉 배낭 밖의 정점 가운데 거리 라벨 d가 최소인 정점 u를 배낭에 넣는다. 👉 u에 인접한 정점들의 라벨을 갱신한다.
결과적으로, 최소신장트리의 Prim-Jarnik알고리즘과 매우 흡사한 것을 느낄 수 있다.
Alg DijkstraShortestPaths(G,s)
input a simple undirected weighted graph G with nonnegative edge weights, vertex s of G
ouput lable d(u), for each vertex u of G, s.t. d(u) is the distance from s to u in G
for each ∈ G.vertexs()
d(v) <- ∞ // 모든 정점의 거리는 0
d(s) <- 0 // 시작 정점 s의 거리는 0
Q <- a priority queue containing all the vertexs of G using d labels as keys
while(!(Q.isEmpty())
u <- Q.removeMin() // 힙으로 구현한, Q 에서, 최소힙의 루트키를 반환해서, 최소 값 정점 u를 반환
for each e ∈ G.incidentEdges(u) // u에 부착된 간선들 전부에 대해
z <- G.opposite(u,e) // z는 정점 u와 부착된 간선을 통한 반대편 정점
if(z ∈ Q.elements()) // 그 정점 z가 아직 Q에 존재하는, 즉, 아직 배낭에 들어가지 못한 정점이면
if(d(u) + w(u,z) < d(z)) // 간선완화진행 ( 기존의 정점 z의 distance보다 > 앞선 u정점과 이어진 간선 (u,z)의 distance의 합이 더 작으면
d(z) <- d(u) + w(u,z) // d(z) 업데이트
Q.replaceKey(z,d(z)) // 그리고, z정점의 가중치가 업데이트 됬으면, 전체, Q 구조 업데이트
추가설명
👉 배낭(Sack) : 가상이므로, 구현하지 않음 !! 👉 우선순위 큐가, 배낭 밖의 정점들을 보관한다. = ( 키(distance)-원소(vertex) ) 👉 각 정점 v에 두 개의 라벨을 저장 = ( 거리( distance ) : d(v) , 부모 정점( parent ) : p(v) )
📢 간선완화
간선 e = (u,z)에 대해 고려한다.
👉 u는 가장 최근에 배낭에 들어간 정점 👉 z는 배낭 밖에 존재하는 정점
간선 e의 완화(relaxation)를 통해 거리 d(z)를 갱신한다. 즉,
👉 d(z) <- min( d(z) , d(u) + w(u,z) )
간선 완화(edge relaxation) 예시
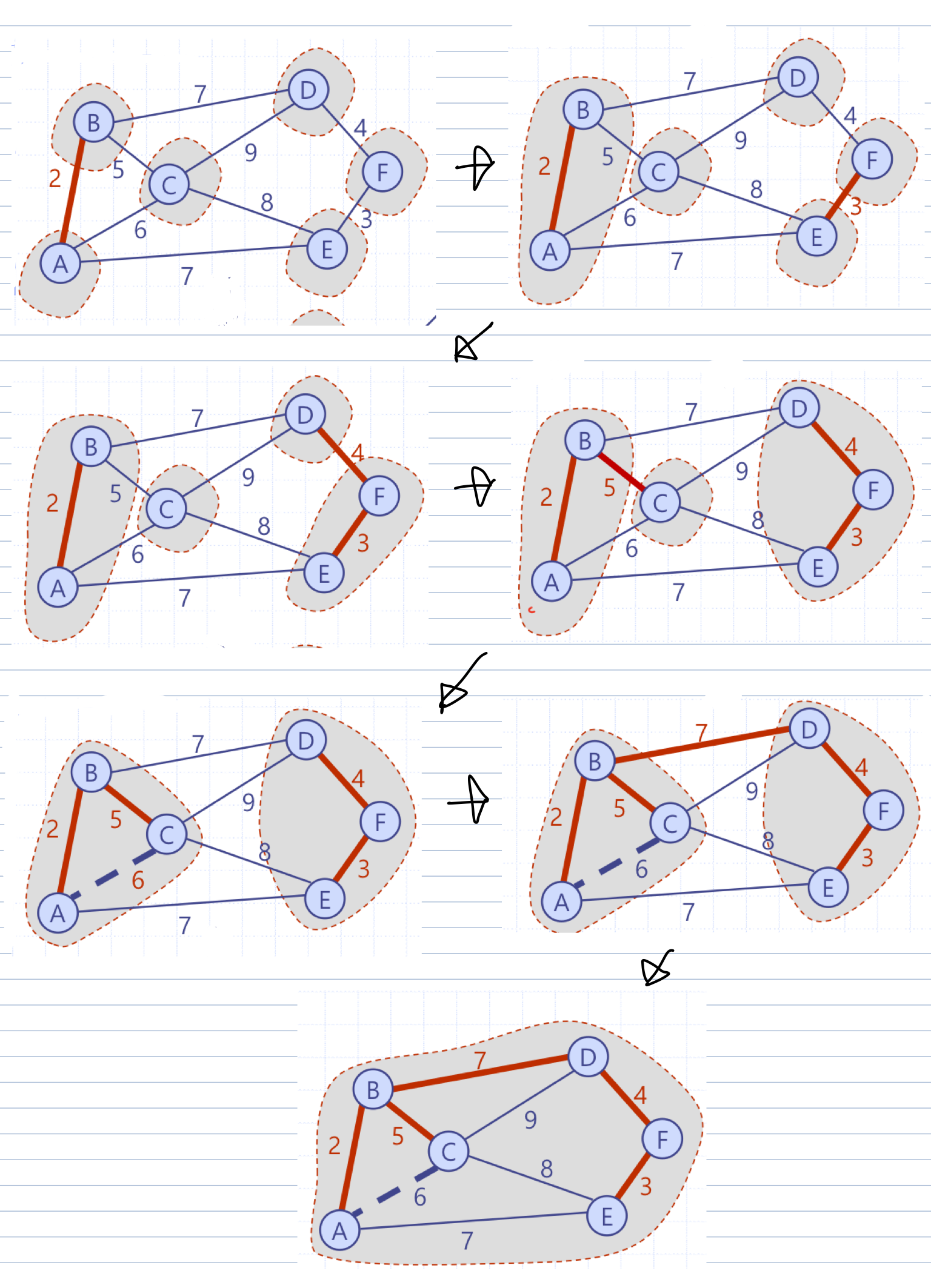
Dijkstra 알고리즘 예시 ( A부터 시작해서, 배낭에 추가되는 것, 동시에 주변 정점에 써있는 distance의 변화를 유의 )
알고리즘 분석
👉 우선순위 큐의 구현에, 두 가지 선택 가능
1. 힙 구현 2. 무순리스트 구현
힙에 기초한 우선순위 큐를 사용할 경우
각 정점은 우선순위 에 한번 삽입, 한번 삭제되며, 각각의 삽입과 삭제에 = O(log(N)) 시간 소요 우선순위 큐 내의 정점 z의 키는 최대 deg(z)번 갱신되며 각각의 키 갱신에 = O(log(N)) 시간 소요
👉 그래프 G가 인접리스트 구조로 표현된 경우, Dijkstra 알고리즘 = O((N+M)log(N)) 시간에 수행 👉 그래프가 연결되어 있으므로, 실행시간 = O(Mlong(N)) 표현 가능 👉 그래프가 단순하다고 전제하므로 = (최악의 경우) O(N^2log(N))
무순리스트에 기초한 우선순위 큐를 사용할 경우
각 정점은 우선순위 큐에 한번 삽입, 한번 삭제되며, 삽입과 삭제에 = 삽입( O(1) ), 삭제( O(N) ) 시간 소요 우선순위 큐 내의 정점 z의 키는 최대 deg(z)번 갱신되며 각각의 키 갱신에 O(1) 시간 소요
👉 그래프가 인접리스트 구조로 표현된 경우, Dijkstra 알고리즘 = O(N^2 + M) 시간에 수행 👉 그래프가 단순하다고 전제하므로 = O(N^2)로 단순화 가능
결과적으로, 두 가지 우선순위 큐 구현 비교 ( 힙 vs 무순리스트 )
👉 힙으로 구현하면 = O(Mlog(N)) 시간 소요 👉 무순리스트로 구현하면 = O(N^2) 시간 소요
👉 두 구현 모두 : 코딩하기 쉽고, 상수적 요소로 보면 비슷하다. 👉 (최악의 경우만을) 생각하면, 다음과 같은 선택지가 있다.
1. 희소그래프( 즉, M < (N^2)/log(N) )에 대해서는 힙 구현이 유리 2. 밀집그래프( 즉, M > (N^2)/log(N) )에 대해서는 구현이 유리
📢 Bellman-Ford 알고리즘
음의 무게를 가진 간선이 있더라도 작동한다.
방향간선으로 전제한다 = If ) 그렇지 않으면, 음의 무게를 가진 싸이클이 있게 되기 때문이다.
i - 번째 회전 시에 i 개의 간선을 사용하는 최단경로를 찾는다.
실행시간 : O(NM)
BFS에 기초한다. = 음의 무게를 가지는 싸이클이 있는 경우, 이를 발견 가능하다.
인접정보를 사용하지 않으므로, 간선리스트 구조 그래프에서 수행 가능하다.
Alg Bellman-FordShortestPaths(G,s)
input a weighted digraph G with n vertexs, and a vertex s of G
output label d(u), for each vertex u of G, s.t. d(u) is the distance from s to u in G
// 그래프 내의 모든 정점 distance = ∞
for each v ∈ G.vertexs()
d(v) <- ∞
d(s) <- 0 // 시작 정점 s에 distance = 0
for i <- 1 to n - 1
for each e ∈ G.edges() // 그래프 내의 모든 간선으로 부터
// 간선완화
u <- G.Origin(e) // u는 간선 e에 저장된 origin(시작) 정점
z <- G.opposite(u,e) // z는 정점 u와 간선 e로 부터 이어지는 반대편 정점
d(z) <- min(d(z),d(u) + w(u,z)) // 현재 정점 z의 distance > u정점까지 거쳐 + u와 z정점으로 이어지는 간선 e의 거리의 합 중에 작은 것을 z의 거리로 업데이트
Bellman-Ford 알고리즘 예시 ( BFS 특징 : 한 칸식 늘려가면서 업데이트 하는 느낌 유의 )
📢 모든 쌍 최단경로
모든 쌍 최단경로(all-pair shortest paths) 문제 : 가중 방향그래프 G의 모든정점쌍 간의 거리를 찾는 문제
그래프에 음의 무게를 가진 간선이 없다면, Dijkstra 알고리즘 N번 호출할 수도 있다. = O(NMlog(N))
그래프에 음의 무게를 가진 간선이 있다면, Bellman-Ford 알고리즘 N번 호출할 수도 있다 = O((N^2)M)
대안
👉 동적프로그래밍(Dynamic Programming)을 사용 = O(N^3) 시간에 수행 가능하다. ( Floyed-Warshall 알고리즘과 유사한 방식으로 수행한다. )
Alg allPairsShortestPaths(G)
input a simple weighted digraph G without negative-weight cycle // 음의 가중치 싸이클 그래프
output a numbering V1,V2,....,Vn of the vertexs of G and a matrix D
(s.t D[i,j] = distance of Vi,Vj in G
Let V1,V2,.....,Vn be an arbitrary numbering of the vertexs of G
for i <-1 to n
for j <- 1 to n
if(i == j)
D[i,j] <- 0 // 자기 자신 distacne = 0
elseif((Vi,Vj) ∈ G.edges())
D[i,j] <- w(Vi,Vj)
else
D[i,j] <- ∞
for k <- 1 to n
for i <-1 to n
for j <- 1 to n
D[i,j] <- min( D[i,j], D[i,k] + D[k,j] )
가중그래프(Weighted Graph) : 각 간선이 무게(weight)라 부르는 수치값을 가지는 그래프
무게가 될 수 있는 것들은 거리,비용,시간 등 다양하다.
가중그래프의 예시
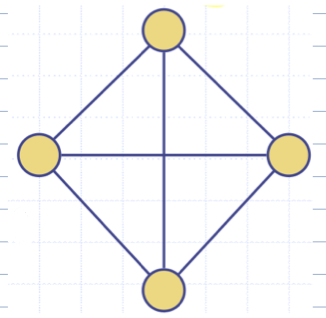
📢 최소신장트리
신장 부그래프(Spanning Subgraph) : 그래프 G의 모든 정점들을 포함하는 부그래프
신장트리(Spanning Tree) : (자유)트리인 신장 부그래프
최소신장트리(MST, Minimum Spanning Tree) : 가중그래프의 총 간선 무게가 최소인 신장트리
응용분야
👉 교통망, 통신망 등등
최소신장트리 예시 ( 파란색 경로가 추가될 경우 Cycle 생성됨 X )
최소신장트리 속성
👉 1. 싸이클속성 👉 2. 분할 속성
이 두개의 속성은 알고리즘의 정확성 검증에 이용한다.
📢 싸이클 속성
f를 e로 대체하면 더 좋은 신장트리를 얻는다.
싸이클 속성
👉 T를 가중그래프 G의 최소신장트리라 가정하자. 👉 e를 T에 존재하지 않는 G의 간선으로, C를 e를 T에 추가하여 형성된 싸이클로 가정하자. 👉 그러면 C의 모든 간선 f에 대해, weight(f) <= weight(e) 이다.
증명
👉 모순법 : 만약 weight(f) > weight(e)라면, f를 e로 대체함으로써 무게가 더 작은 신장트리를 얻을 수 있기 때문
📢 분할 속성
분할 속성
👉 G의 정점들을 두 개의 부분집합 U와 V로 분할한다고 하자. 👉 e를 분할을 가로지르는 최소 무게의 간선이라고 하자. 👉 간선 e를 포함하는 G의 최소신장트리가 반드리 존재한다.
증명
👉 T를 G의 MST라 하자. 👉 만약 T가 e를 포함하지 않는다면, e를 T에 추가하여 형성된 싸이클 C를 구성하는 간선들 가운데 분할을 가로지르는 간선 f가 존재할 것이다. 👉 싸이클 속성에 의해, weight(f) <= weight(e) 👉 그러므로, weight(f) == weight(e) 👉 f를 e로 대체하면 또 하나의 MST를 얻을 수 있다.
📢 최소신장트리 알고리즘
크게 3가지 알고리즘이 존재한다.
👉 1. Prim-Jarnik 알고리즘 ( 많이 씀 ) 👉 2. Kruskal 알고리즘 ( 많이 씀 ) 👉 Baruvka 알고리즘 ( 1번 + 2번 느낌 )
📢 Prim-Jarnik 알고리즘
탐욕(Greedy) 알고리즘의 일종
대상 : 단순 연결 무방향 그래프
아이디어
👉 임의의 정점 s를 택하여, s로부터 시작해서, 정점들을 (가상의)배낭에 넣어가며 배낭 안에서 MST T를 키워 나감 👉 s는 T의 루트(root)가 될 것이다. 👉 각 정점 v에 라벨 d(v)를 정의 = d(v)는 배낭 안에 정점과 배낭 밖 정점을 연결하는 간선의 weight 👉 반복의 각 회전에서 : 배낭 밖 정점들 가운데 최소 d(z) 라벨을 가진 정점 z를 배낭에 넣고, z에 인접한 정점들의 라벨을 갱신한다.
Alg PrimJarnikMST(G)
input a simple connected weighted graph G with n vertexs and m edges
output an MST T for G
for each v ∈ G.vertexs()
d(v) <- ∞ // 여기서, d(v)는 각 정점들의 거리
p(v) <- ∅ // 여기서, p(v)는 각 정점들의 MST로 이뤄지기위한 직계 부모 정점 정보
s <- a vertex of G
d(s) <- 0
Q <- a priority queue containing all the vertexs of G using d labels as keys
while(!(Q.isEmpty()) // 우선순위 큐를 비울 때까지 반복인데, 반복 작업은, 배낭(MST)에 정정을 하나씩 넓혀가는 것
u <- Q.removeMin() // 우선순위 큐에 들어가있는, 가장 거리 d 가 작은 정점 반환 u
for each e ∈ G.incidentEdges(u) // 정점 u에 부착된 간선 전부를 본다.
z <- G.opposite(u,e) // 정점 u와 이어진 간선 e를 통한 반대편 정점을 z라 한다.
if((z ∈ Q) & (w(u,z) < d(z))) // 정점 z가 우선순위 큐에 있는 것이고, 즉 아직 방문 안한 정점이고, 정점 u를 거쳐 정점 z로 가는 거리가, 아직 현재 정점 z거리보다 적으면
d(z) <- w(u,z) // 정점 z의 거리를 업데이트한다.
p(z) <- e // 그리고, 정점 z의 부모간선을 e로 업데이트한다.
Q.replaceKey(z,w(u,z)) // 이렇게, 정점 z의 거리(d)가 우선순위가 바꼈을 수도 있으니, 우선순위큐 재배치를 진행한다.
추가설명
👉 (가상의)배낭 밖의 정점들을 우선순위 큐에 저장 : 키(거리)-원소(정점정보) 👉 각 정점 v에 세 개의 라벨을 저장한다.
1. 거리(distance) : d(v) 2. 위치자(locator) : 우선순위 큐에서의 v의 위치 3. 부모(parent) : p(v), MST에서 v의 부모를 향한 간선
ㅌPrim-Jarnik 알고리즘 예시
알고리즘 분석
👉 라벨 작업 : 점정 z의 거리, 부모, 위치자 라벨을 O(deg(z))시간 읽고 쓴다. 라벨을 읽고 쓰는데 O(1)시간 소요 👉 우선순위 큐( 힙으로 구현할 경우 ) 작업
1. 각 정점은 우선순위 큐에 한번 삽입되고 한번 삭제 : 삽입과 삭제에 각각 O(log(N))시간 소요 2. 우선순위 큐 내의 정점 w의 키는 최대 deg(w)번 변경 : 각 키 변경에 O(log(N))시간 소요 (힙 이니깐)
👉 그래프가 인접리스트 구조로 표현되어 있다면, Prim-Jarnik 알고리즘은 O((N+M)log(N))시간에 수행한다. 👉 단순 연결그래프에서 N = O(M)이므로, 총 실행시간 : O(Mlog(N))
📢 Kruskal 알고리즘
탐욕(Greedy) 알고리즘
알고리즘을 위한 초기 작업
👉 모든 정점을 각각의 독자적인 (실제의)배낭에 넣는다. 👉 배낭 밖 간선들을 우선순위 큐에 저장한다. = 키(무게)-원소(간선) 👉 비어 있는 MST T를 초기화
반복의 각 회전에서 : 두 개의 다른 배낭 속에 양끝점을 가진 최소 무게의 간선을 MST T에 포함하고 두 배낭을 하나로 합친다.
반복이 완료되면 : MST T를 포함하는 한 개의 배낭만 남게 될 것이다.
Alg KruskalMST(G)
input a simple connected weighted graph G with n vertexs and m edges
output an MST T for G
for each v ∈ G.vertexs()
define a Sack(v) <- {v} // Sack은 배낭을 의미, 이것은 실제 구현에서는 Parent(v)로 제어하면 편하다.
Q <- a priority queue containnig all the edges of G using weights as keys
T <- ∅
while(T has fewer than n - 1 edges)
(u,v) <- Q.removeMin()
if(Sack(u) ≠ Sack(v))
Add edge (u,v) to T
Merge Sack(u) and Sack(v)
return T
아Kruskal 알고리즘 예시
알고리즘 분석
👉 우선순위 큐 초기화 작업
힙을 사용하여 우선순위 큐 Q를 구현하면, 반복적인 삽입 방식에 의해서는 O(Mlog(M))시간에, 상항식 힙 생성 방식에 의해서는O(M) 시간에 Q 생성이 가능하다.
👉 반복의 각 회전에서는
최소 무게의 간선을 O(log(M))시간에 삭제 가능 = 여기서, G가 단순그래프이므로, O(log(M)) = O(log(N)) 각 배낭을 위한 분리집합을 리스트로 구현하면, find(u) ≠ find(v) 검사에 O(1) 시간 ( 또는 parent 배열을 이용 ! ) 두 개의 배낭 Sack(u), Sack(v)를 합치는데 O(min( |Sack(u)|, |Sack(v)| )) 시간 소요 ( 더 작은 배낭을 옮김 )
👉 총 반복 회수 : (최악의 경우) M번 👉 그러므로, Kruskal 알고리즘은O((N + M)log(N)) 시간에 수행 👉 G가 단순 연결그래프인 경우 N = O(M)이므로, 실행시간은 O(Mlog(N)) 이다.
📢 MST 알고리즘 비교
알고리즘
주요전략
수행시간
외부 데이터구조
Prim-Jarnik
탐욕
O(Mlog(N))
정점들을 저장하기 위한 우선순위 큐
Kruskal
탐욕
O(Mlog(N))
1. 간선들을 저장하기 위한 우선순위 큐 2. 배낭들을 구현하기 위한 분리집합(리스트로 구현가능) or 각 정점에 대해 부모정점(Parent배열)배열을 이용하는 방법
동적프로래밍(DP, Dynamic Programming) : 알고리즘 설계의 일반적 기법 중 하나
언뜻 보기에 많은 시간( 심지어 지수 시간 )이 소요될 것 같은 문제에 주로 적용한다.
적용의 조건은 :
👉 부문제 단순성(Simple Subproblems) : 부문제들이 j,k,l,m 등과 같은 몇 개의 변수로 정의 될 수 있는 경우 👉 부문제 최적성(Optimality Subproblems) : 전체 최적치가 최적의 부문제들에 의해 정의될 수 있는 경우 👉 부문제 중복성(Overlap Subproblems) : 부문제들이 독립적이 아니라 상호 겹쳐질 경우 ( 즉, 상향식으로 구축 )
대표적 예시
👉 피보나치 수(Fibonacci progression)에서 N-번째 수 찾기 👉 그래프의 이행적폐쇄 계산하기
동적프로그래밍 vs 분할통치법
공통점
👉 알고리즘 설계기법의 일종 👉 문제공간 : 원점-목표점 구조 ( 원점 : 문제의 초기 또는 기초지점 / 목표점 : 최종해가 요구되는 지점 )
차이점
👉 문제해결 진행 방향
동적프로그래밍(단방향) : 원점 -> 목표점 분할통치법(양방향) : 목표점 -> 원점 -> 목표점 ( 단, 해를 구하기 위한 연산을 진행, 방향은 원점->목표점 )
성능
👉 동적프로그래밍 : 단방향 특성때문에 종종 효율적 👉 분할통치법 : 분할 회수(보통 2분할을 한다.) , 중복연산 수행 회수에 따라 다름
이름은 "동적"프로그래밍이지만, 실제로 우리가 아는 "동적", 그때그때 사용하는 그런 의미는 아니다. 하나 구한 것은, 다를 때, 사용하는 의미일 뿐이고, 이러한 기법의 이름을 지은 사람이 그냥 "동적프로그래밍"이라 작명한 것 일 뿐이다. 오해하지말자.
📢 동적프로그래밍 예시
N-번째 피보나치 수 찾기 : 피보나치 수열(Fibonacci Progression)은 i = 0,1에 대해 f(i) = 1이며, i >= 2 에 대해 f(i) = f(i-1) + f(i-2)인 수열이다.
f(n), 즉 피보나치 수열의 n-번째 수를 찾기 위해, 정의로부터 직접 재귀알고리즘 f를 작성할 수도 있지만, 불행히도 지수시간(exponential time)에 수행하므로 너무나 비효율적이다 !!
이를, 동적프로그래밍에 기초하여 f(n)을 찾는 비재귀, 선형시간 알고리즘을 다음 두 버젼으로 작성해보자.
👉 1. 선형공간으로 수행하는 버젼 👉 2. 상수공간으로 수행하는 버젼
Alg f(n) // 선형 공간
if(n == 0 || n == 1)
return 1
A[0] <- 1
A[1] <- 1
for i <- 2 to n
A[i] <- A[i-1] + A[i-2]
return A[n]
=============================
Alg f(n) // 상수 공간
if(n == 0 || n == 1)
return 1
a <- 1
b <- 1
for i <- 2 to n
c <- a + b
a <- b
b <- c
return c
👉 M <= N(N-1) 이다. ( 무방향그래프에선 M <= (N(N-1)/2 였다. ) ( 여기서 M = 간선 수, N = 정점 수 이다. )
진입간선들(in-edges)과 진출간선들(out-edges)을 각각 별도의 인접리스트로 보관한다면, 진입간선들의 집합과 진출간선들의 집합을 각각의 크기에 비례한 시간에 조사 가능하다.
방향 그래프의 예시위에 그래프 기준으로, in-edges, out-edges를 표현하면 이런느낌
📢 방향 DFS
간선들을 주어진 방향만을 따라 순회하도록 하면, DFS 및 BFS 순회 알고리즘들을 방향그래프에 특화 가능하다.
방향 DFS 알고리즘에서 네 종류의 간선이 발생한다.
👉 트리간선(tree edges) : 트리에서, DFS경로에 해당하는 간선 👉 후향간선(back edges) : 트리에서 나의 조상방향으로 그려질 간선 👉 전향간선(forward edges) : 트리에서 나의 자식이 아닌, 더 아래 자식 정점의 경우 그려질 간선 👉 교차간선(cross edges) : 같은 레벨이나 하위레벨 정점끼리의 연결 간선
정점 s에서 출발하는 방향 DFS 👉 s로부터 도달 가능한 정점들을 결정한다.
위에 그래프를 통해 그려지는 DFS tree
도달 가능성이란 ?
👉 방향그래프 G의 두 정점 v와 u에 대해, 만약 G에 v에서 u로의 방향 경로가 존재한다면, "v는 u에 도달한다" 또는 "u는 v로부터 도달 가능하다" 를 의미한다. 👉 s를 루트로 하는 DFS 트리 : s로부터 방향경로를 통해 도달 가능한 정점들을 표시한 것
그래프 G에서 어떤 정점 s에서 "도달가능한" 예시
📢 강연결성
방향그래프 G의 어느 두 정점 u와 v에 대해서나 u는 v에 도달하며 v는 u에 도달하면
👉 G를 강연결(strongly connected)이라고 말한다. 즉, 어느 정점에서든지 다른 모든 정점에 도달 가능하다.
이런 방향그래프가 있다 가정하자.
강연결 검사 알고리즘
👉 1. 그래프 G의 임의의 정점 v를 선택한다. 👉 2. 그래프 G의 v로부터 DFS를 수행한다. ( 방문되지 않은 정점 w가 있다면, False를 반환한다. ) 👉 3. 그래프 G의 간선들을 모두 역행시킨 그래프 G` 를 얻는다. 👉 4. G`의 v로부터 DFS를 수행한다. ( 방문되지 않은 정점 w가 있다면, False를 반환. 그렇지 않으면, True 반환)
실행시간 = O(N + M)
그래프 G와 G의 역행방향인 G` 에 대해 DFS 실행한 결과 ( 두 경우 모두 모든 정점을 전부 방문한 것을 확인 )
강연결요소
👉 방향그래프서 각 정점으로 다른 모든 정점으로 도달할 수 있는 최대의 부 그래프 👉 DFS를 사용하여 O(N + M)시간에 계산 가능하다.
강연결요소의 예시. ( 방향그래프에 싸이클 집합을 찾아보면 된다. ), 위에 예제는 강연결요소가 2개
📢 이행적폐쇄
주어진 방향그래프 G에 대해, 그래프 G의 이행적폐쇄(Transitive Closure)는 다음을 만족하는 방향그래프 G*
👉 G* 는 G와 동일한 정점들로 구성 👉 G에 u로부터 v ≠ u 로의 방향경로가 존재한다면,G*에 u로부터 v로의 방향간선이 존재한다. 👉 더 쉽게, 수학적으로, "A -> B , B -> C 이면, A -> C" 를 의미하는 것
이행적폐쇄는 방향그래프에 관한 도달 가능성 정보를 제공한다.
방향그래프 G와 이행적폐쇄를 만족하는 방향그래프 G*
이행적폐쇄 계산
👉 각 정점에서 출발하여 DFS를 수행할 수 있다.
실행시간 : O(N(N + M))) 👉 N개의 각 정점의 대해 * DFS
대안으로, 동적프로그래밍(DP, Dynamic Programming)을 사용할 수 있다.
👉 Floyed-Warshall 알고리즘 : 위에서 설명한, "A -> B , B -> C 이면, A -> C"
📢 Floyed-Warshall 이행적폐쇄
정점들을 1,2,....n으로 번호를 매긴다.
1,2,....,k로 번호 매겨진 정점들만 경유 정점으로 사용하는 경로들을 고려해본다.
Floyed-Warshall 이행적폐쇄 예시
Alg Floyed-Warshall(G)
input a digraph G with n vertexs
output transitive closure G* of G
Let V(1),V(2),...,V(n) be an arbitrary numbering of the vertexs of G
G(0) <- G
for k <- 1 to n // Stopover vertex
G(k) <- G(k-1)
for i <- 1 to n, i ≠ k // start vertex
for j <- 1 to n, j ≠ i,k // end vertex
if(G(k-1).areAdjacent(V(i),V(k) & G(k-1).areAdjacent(V(k),V(j))
if(!(G(k).areAdjacent(V(i),V(j))
G(k).insertDirectedEdge(V(i),V(j),k)
return G(n)
Floyed-Warshall 알고리즘은 G의 정점들을 V(1),....,V(n)으로 번호 매긴 후, 방향그래프 G(0),....,G(n)을 잇달아 계산
👉 G(0) = G 👉 G에 { V(1),....V(k) } 집합 내의 경유정점을 사용하는 V(i)에서 V(j)로의 방향경로가 존재하면 G(k)에 방향간선 (V(i), V(j))를 삽입
k 단계에서, 방향그래프 G(k-1)로부터 G(k)를 계산
마지막에 G(n) = G*를 얻음
실행시간 : O(n^3)
👉 전제 : 인접한지 알아보는 areAdjacent( )가 O(1)시간에 수행 ( 즉, 인접행렬 버젼일 경우 )
n = 5 인 방향그래프 G의 Floyed-Warshall 이행적폐쇄 진행과정 예시
📢 방향 비싸이클 그래프
방향 비싸이클 그래프(DAG, Directed Acyclic Graph) : 방향싸이클이 존재하지 않는 방향그래프
예시
👉 클래스 간 상속 또는 인터페이스 👉 교과 간의 선수 관계 등등
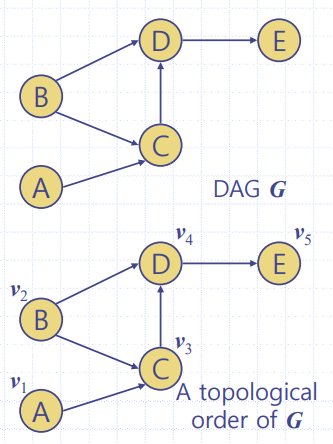
방향그래프의 위상순서(Topological Order)
👉 모든 i < j인 간선 (V(i),V(j))에 대해 정점들을 번호로 나열한 것이다. 👉 예시) 작업스케쥴링 방향그래프에서 위상순서는 작업들의 우선 d 만족하는 작업 순서
결론 : 방향그래프가 DAG 이면 👉 위상순서를 가지며, 그 역도 참이다.
DAG(Directed Acylic Graph)와 DAG의 위상순서
📢 위상정렬(Topological Sort)
위상 정렬(Topological Sort) : DAG로부터 위상순서를 얻는 절차
알고리즘
👉 1. topologicalSort : 정점의 진입차수(in-degree)를 이용한 방법 👉 2. topologicalSortDFS : DFS의 특화된 방법
1. topologicalSort : 정점의 진입차수(in-degree)를 이용한 방법
Alg topologicalSort(G)
input a digraph G with n vertexs
output a topological ordering V(1),...,V(n) of G,
or an indication that G has a directed cycle
Q <- empty queue
for each u ∈ G.vertexs()
in(u) <- inDegree(u)
if(in(u) == 0)
Q.enqueue(u)
i <- 1 // topological number
while(!(Q.isEmpty())
u <- Q.dequeue()
Label u with topological number i
i <- i + 1
for each e ∈ G.outIncidentEdges(u)
w <- G.opposite(u,e)
in(w) <- in(w) - 1
if(in(w) == 0)
Q.enqueue(w)
if(i <= n) // i = n + 1, for DAG
write("G has a directed cycle) // DAG가 아님을 알리는 메시지
return
// 각 정점에 새로운 라벨을 정의 => 현재 진입차수(inCount) : in(v) => 정점 v의 현재의 진입차수 계산
topologicalSort : 정점의 진입차수(in-degree)를 이용한 방법 예시
2. topologicalSortDFS : DFS를 활용한 위상정렬
Alg topologicalSortDFS(G)
input DAG G
output topological ordering of G
n <- G.numVertexs()
for each u ∈ G.vertexs()
l(u) <- Fresh
for each v ∈ G.vertexs()
if(l(v) == Fresh)
rTopologicalSortDFS(G,v)
=========================================
Alg rTopologicalSortDFS(G,v) // 재귀적 DFS를 활용한 위상정렬
input graph G, and a start vertex v of G
output labeling of the vertexs of G
in the connected component of v
l(v) <- Visited
for each e ∈ G.outIncidentEdges(v)
w <- opposite(v,e)
if(l(w) == Fresh) // 간선 e는 tree 간선
rTopologicalSortDFS(G,w)
Label v with topological number n
n <- n - 1 // 전역 변수로 제어할 것이다.
topologicalSortDFS : DFS를 활용한 위상 정렬 방법 예시
위상 정렬 알고리즘 비교
1. topologicalSort : 정점의 진입차수를 이용한 버젼
👉 O(N + M) 시간과 O(N) 공간 소요 👉 그래프 G가 DAG라면 위상순서를 계산 👉 그래프 G에 방향싸이클이 존재할 경우, 일부 정점의 순위를 매기지 않은 채로 "정지"
2. topologicalSortDFS : DFS 활용한 버젼
👉 O(N + M) 시간과 O(N) 공간 소요 👉 그래프 G가 DAG라면 G의 위상순서를 계산 👉 그래프 G에 방향싸이클이 존재할 경우, 허위의 위상순서를 계산 = 방향싸이클을 발견하도록 수정 가능함 !!
Alg DFS(G)
input graph G
output labeling of the edges of G
as tree edges and back edges
for each u ∈ G.vertexs()
l(u) <- Fresh
for each e ∈ G.edges()
l(e) <- Fresh
for each v ∈ G.vertexs()
if(l(v) == Fresh)
rDFS(G,v) // 재귀적 DFS 호출
=======================================================
Alg rDFS(G,V) // 재귀적 DFS
input graph G and a start vertex v of G
output labeling of the edges of G in the connected
component of v as tree edges and back edges
l(v) <- Visited // 방문한 노드 체크
for each e ∈ G.incidentEdges(v) // 정점 v에 부착된 간선에 대해
if(l(e) == Fresh) // 간선 e가 아직 안지나간 간선이면
w <- G.opposite(v,e) // 정점 v와 간선 e를 통한 반대편 정점 w
if(l(w) == Fresh) // w가 아직 미방문 정점이면
l(e) <- Tree // 일단, 간선 e는 Fresh -> Tree 간선으로 변경
rDFS(G,w) // rDFS 재귀호출
else // 간선 e가 Fresh한 간선이 아니다 ?
l(e) <- Back // 그럼, 간선 e는 Fresh -> Back 간선으로 변경
DFS 수행 예시
DFS 처리 예시
DFS 속성
👉 속성 1. rDFS(G,v)는 v의 연결요소내의 모든 정점과 간선을 방문한다. 👉 속성 2. rDFS(G,V)에 의해 라벨된 트리 간선들은 v의 연결요소의 신장트리(DFS tree)를 형성한다.
DFS 분석
👉 정점과 간선의 라벨을 쓰고 읽는데 O(1)시간 소요 👉 각 정점은 두 번 라벨 ( 한 번은 Fresh, 또 한번은 Visited ) 👉 각 간선은 두 번 라벨 ( 한 번은 Fresh, 또 한번은 Tree 또는 Back 으로 ) 👉 incidentEdges( ) ( 한 정점에 붙어있는 부착간선 메소드 )는 각 정점에 대해 한 번 호출 👉 그래프가 인접리스트 구조로 표현된 경우, DFS는 O(N + M)시간에 수행 ( 어떤 그래프 G의 deg(v) 합 = 2M )
DFS 템플릿 활용
👉 연결성 검사, 경로 찾기, 싸이클 찾기 등의 문제들을 DFS를 확장해서 해결할 수 있다.
📢 비재귀적 DFS
rDFS ( 재귀 DFS )는 이름 그대로, 재귀호출을 통해서 그래프 순회를 한다.
비재귀적 DFS는 재귀호출이 아닌, 스택(Stack)을 사용해서 DFS를 실행한다.
Alg DFS(G,v)
input graph G and a start vertex v of G
output labeling of the edges of G
in the connected component of v
as tree edges and back edges
S <= empty stack
S.push(v) // 매개변수 v정점 스택에 push
while(!(S.isEmpty()) // 스택을 비울동안
v <= S.pop() // 스택 pop()
l(v) <- Visited // pop()한 정점는,이제 Visited
for each e ∈ G.incidentEdges(v) // pop()한 정점에 부착된 모든 간선에 대해
if(l(e) == Fresh) // 그 간선이 아직 방문안한 간선이면
w <- G.opposite(v,e) // pop()한 정점 v와 연결된 간선 e의 반대편 정점이 w
if(l(w) == Fresh) // 그 정점 w가 아직 방문안한 정점이면 ?
l(e) <- Tree // 건너언 간선 e는 일단 Fresh -> Tree 간선으로 변경
S.push(w) // 그리고, w정점을 스택에 push
else // 정점 w가 이미 방문한 정점이면
l(e) <- Back // 건너온 간선 e는 Fresh -> Back 간선으로 변경 ( 싸이클 제어 )
return
실제 구현 ( By. C )
// DFS 비재귀버젼
#include <stdio.h>
#include <stdlib.h>
typedef struct incidentedge
{
int key;
char state[6];
struct incidentedge* next;
struct incidentedge* prev;
}IncidentEdge;
typedef struct vertex
{
int key;
char state[6];
IncidentEdge* head;
}Vertex;
typedef struct stack // 비재귀 DFS를 위한 stack ( 정점의 키값을 저장할것이다. )
{
int* list;
int top;
}Stack;
void nrDFS(Vertex* V, int S, int n); // 비재귀 DFS
void makeVertex(Vertex* V, int n);
void linkEdge(Vertex* V, int start, int end);
void initStack(Stack* S, int n); // 스택 초기화
void push(Stack* S, int n); // 스택 push
int pop(Stack* S); // 스택 pop
int isStackEmpty(Stack* S); // 스택 비었는가 ?
void freeVertexIncidentList(Vertex* V, int n);
int main()
{
int N, M, S, start, end;
Vertex* v = NULL;
scanf("%d %d %d", &N, &M, &S);
v = (Vertex*)malloc(sizeof(Vertex) * N);
makeVertex(v, N);
for (int i = 0; i < M; i++)
{
scanf("%d %d", &start, &end);
linkEdge(v, start, end);
linkEdge(v, end, start);
}
nrDFS(v,S,N); // 비재귀 DFS 호출만 다른 부분
freeVertexIncidentList(v, N); // 각 정점에 달린, 인접 리스트 동적할당 해제
for (int i = 0; i < N; i++)
free(v[i].head); // 각 정점에 달린, 인접헤드 동적할당 해제
free(v); // 정점배열 동적할당 해제
return 0;
}
void nrDFS(Vertex* V,int s,int n) // 비재귀적 DFS
{
IncidentEdge* p = NULL; // 인접리스트 조사할 p
Stack* stack = NULL; // 스택 포인터
stack = (Stack*)malloc(sizeof(Stack)); // 스택 동적할당
initStack(stack,n); // 스택 초기화
push(stack, V[s - 1].key); // 파라미터로 넘어온 s, 정점 s부터 시작, 스택에 push
strcpy(V[s - 1].state, "visit"); // 정점 s 는 이제 visit
printf("%d\n", V[s-1].key); // 방문의미하는 출력
while (!isStackEmpty(stack)) // 이제부터 스택이 비울 때까지 반복할 것임
{
// 매 차례마다
p = V[stack->list[stack->top]-1].head->next; // 스택에 가장 최근에 들어온, 정점위치의, 인접노드 시작을 p에 대입해서
while (p != NULL && strcmp(V[p->key - 1].state, "visit") == 0) // 인접해 있는데, 아직 방문안한, 정점 찾음
p = p->next;
if (p != NULL && strcmp(V[p->key-1].state,"fresh") == 0) // 아직 방문안한, 인접한 정점이 있으면
{
push(stack, V[p->key - 1].key); // 그 정점, 스택에 push
strcpy(V[p->key - 1].state, "visit"); // 그 정점은 이제, visit
printf("%d\n", V[p->key - 1].key); // 그 정점으로, 방문했음을 의미,출력
}
if (p == NULL) // 윗 while문을 통해서, 현재 stack에 peek한 정점의, 인접 정점을 다 방문했으면
pop(stack); // 그 정점은, 이제 들어갈 만큼 들어간 것이니, pop
}
free(stack->list); // 스택 리스트 동적할당 해제
free(stack); // 스택 동적할당 해제
}
void makeVertex(Vertex* V, int n)
{
for (int i = 0; i < n; i++)
{
V[i].key = i + 1;
strcpy(V[i].state, "fresh");
V[i].head = (IncidentEdge*)malloc(sizeof(IncidentEdge));
if (V[i].head != NULL)
{
V[i].head->next = NULL;
V[i].head->key = 0;
}
}
}
void linkEdge(Vertex* V, int start, int end)
{
IncidentEdge* p, * newNode;
newNode = (IncidentEdge*)malloc(sizeof(IncidentEdge));
if (newNode != NULL)
{
newNode->key = end;
newNode->prev = NULL;
newNode->next = NULL;
strcpy(newNode->state, "fresh");
}
p = V[start - 1].head;
while (p->next != NULL && end > p->next->key)
p = p->next;
if (p->next == NULL)
{
p->next = newNode;
newNode->prev = p;
}
else
{
newNode->next = p->next;
p->next->prev = newNode;
newNode->prev = p;
p->next = newNode;
}
}
void initStack(Stack* S, int n)
{
S->list = (int*)malloc(sizeof(int) * n);
S->top = -1;
}
void push(Stack* S, int n)
{
S->top += 1;
S->list[S->top] = n;
}
int pop(Stack* S)
{
int returnData = S->list[S->top];
S->top -= 1;
return returnData;
}
int isStackEmpty(Stack* S)
{
return S->top == -1;
}
void freeVertexIncidentList(Vertex* V, int n)
{
IncidentEdge* p = NULL;
for (int i = 0; i < n; i++)
{
while (V[i].head->next != NULL)
{
p = V[i].head->next;
while (p->next != NULL) p = p->next;
p->prev->next = NULL;
free(p);
}
}
}
📢 너비우선탐색(BFS)
너비우선탐색(BFS, Breadth First Search) : 그래프를 순회하기 위한 일반적 기법 중 하나.
그래프 G에 대한 BFS순회로 가능한 것들
👉 G의 모든 정점과 간선을 방문 👉 G가 연결그래프인지 결정 👉 G의 연결요소들을 계산 👉 G의 신장숲을 계산
N개의 정점과 M개의 간선을 가진 그래프에 대한 BFS는 O(N + M)시간 소요
BFS를 확장하면 해결 가능한 그래프 문제들
👉 두 개의 주어진 정점 사이의 최소 간선을 사용하는 경로를 찾아보기 👉 그래프 내 단순싸이클 찾기
그래프에 대한 BFS는 이진트리에 대한 레벨순회와 유사하다. ( 레벨순회는 큐(Queue)를 활용했었다. ) ( 자료구조의 레벨순회를 모른다면, 아래 포스팅을 확인하고 오길 바란다. )
Alg BFS(G)
input graph G
output labeling of the edges of G
as tree edges and cross edges
for each u ∈ G.vertexs()
l(u) <- Fresh
for each e ∈ G.edges()
l(e) <- Fresh
for each v ∈ G.vertexs()
if(l(v) == Fresh)
BFS1(G,v)
=======================================
Alg BFS1(G,v)
input graph G and a start vertex v of G
output labeling of the edges of G
in the connected component of v as tree
edges and cross edges
L(0) <- empty list // 레벨순회 큐(queue)
L(0).addLast(v) // 큐에 매개변수로 넘어온, 정점 v 를 enqueue
l(v) <- Visited // 정점을 큐에 enqueue 했다는 것은, 방문했다는 의미. 고로 정점 v를 Fresh -> Visited
i <- 0 // 큐 인덱싱할 i
while(!(L(i).isEmpty()) // 큐를 비울때까지
L(i+1) <- empty list
for each v ∈ L(i).elements() // 큐에 있는 정점 하나를 dequeue를 하고
for each e ∈ G.incidentEdges(v) // 그 정점과 연결된 모든 간선에 대해
if(l(e) == Fresh) // 아직 방문안해본 간선이면 가서
w <- G.opposite(v,e) // 그 정점 v와 간선 e를 통한 반대편 정점을 w라 하고
if(l(w) == Fresh) // 그 정점 w가 아직 방문안한 정점이면
l(e) <- Tree // 간선 e는 Fresh -> Tree 간선으로
l(w) <- Visited) // 정점 w는 Fresh -> Visited 정점으로 변경하고
L(i+1).addLast(w) // 정점 w를 큐에 enqueue
else // 정점 w가 이미 방문한 정점이라면
l(e) <- Cross // 간선 e는 Fresh -> Cross 간선으로
i <- i + 1
BFS 수행 예시
BFS 수행 예시
BFS 속성
👉 G(v) : v의 연결요소라 했을 때 👉 속성 1. BFS1(G,v)는 G(v)의 모든 정점과 간선을 방문한다. 👉 속성 2. BFS1(G,v)에 의해 라벨된 트리 간선들은 G(v)의 신장트리(BFS tree)라 불린다. ( T(v) ) 👉 속성 3. L(i)내의 각 정점 w에 대해
1. T(v)의 v에서 w로 향하는 경로는 i개의 간선을 가진다. 2. G(v)내의 v에서 w로 향하는 모든 경로는 최소 i개 간선을 가진다.
BFS 분석
👉 정점과 간선의 라벨을 쓰고 읽는데 O(1) 시간소요 👉 각 정점은 두 번 라벨 ( 한 번은 Fresh로 , 또 한 번은 Visited 로 ) 👉 각 간선은 두 번 라벨 ( 한 번은 Fresh로 , 또 한 번은 Tree 또는 Cross 로 ) 👉 각 정점은 리스트 L(i)에 한 번 삽입 ( 여기서 리스트는 큐(queue)를 의미 ) 👉 incidentEdges( ) ( 부착간선 메소드 )는 각 정점에 대해 한 번 호출 👉 그래프 G가 인접리스트 구조로 표현된 경우, BFS는 O(N + M)시간에 수행
BFS 템플릿 활용
👉 G의 연결요소들을 계산하기 👉 G의 신장숲을 계산하기 👉 G내의 단순 싸이클 찾기 또는 G가 숲임을 보고하기 👉 G의 주어진 두 정점에 대해, 그 사이의 최소 간선로 이루어진 G 내의 경로 찾기, 또는 그런 경로 없음을 찾기 ( 즉, 최단 경로(Directed Path) 문제 활용 가능 )
👉 원소(i,j) = 1 : 정점 i와 정점 j 사이에 간선이 있다. 👉 원소(i,j) = 0 : 정점 i와 정점 j 사이에 간선이 없다.
무향 그래프의 인접행렬은 연결성을 의미한다. ( 1 = 연결됨, 0 = 연결안됨 )
유향 그래프의 경우
👉 원소(i,j)는 정점 i 로부터 정점 j 로 연결되는 간선이 있는지를 나타낸다.
유향 그래프에서 인접행렬 또한 연결성을 의미( 1 = 연결됨, 0 = 연결 안됨 )
가중치 있는 그래프의 경우
👉 원소(i,j)는 1 대신에 가중치를 가진다.
가중 그래프에선 인접행렬의 요소 값은 "가중치" 의미가중 그래프 다른 예시
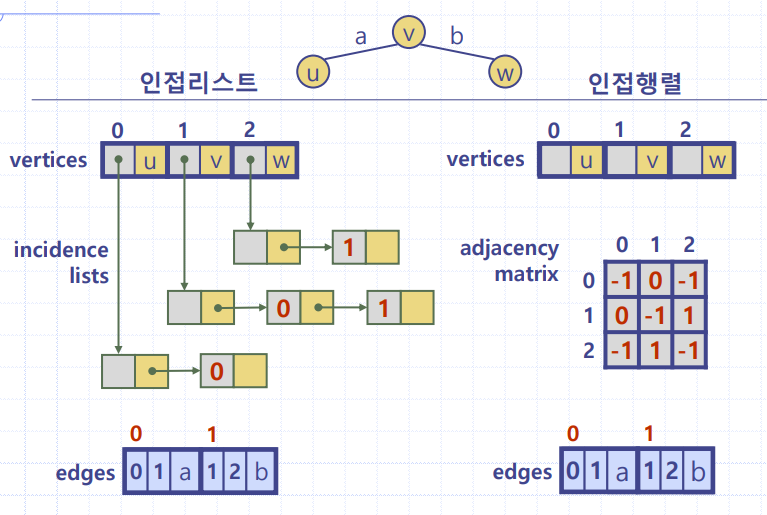
📢 인접리스트(Adjacency List)
N 개의 연결 리스트로 표현
👉 i 번째 리스트는 정점 i 에 인접한 정점들을 리스트로 연결해 놓은 것
가중치 있는 그래프의 경우
👉 리스트는 가중치도 보관한다.
무방향 그래프 인접리스트 예가중치 그래프 인접리스트 예
📢 그래프 성능 & 특징
점근적 성능 비교
N 정점과 M 간선 병렬 간선 없음 루프 없음
간선리스트
인접리스트
인접행렬
공간
N + M
N + M
N^2
incidentEdges(v)
M
deg(v)
N
adjacentVertexs(v)
M
deg(v)
N
areAdjacent(v,u)
M
min(deg(v),deg(u))
1
insertVertex(o)
1
1
N
insertEdge(v,w,o)
1
1
1
removeVertex(v)
M
deg(v)
N
removeEdge(e)
1
1
1
그래프 상세 구현 비교
인접리스트
인접행렬
연결리스트
정점리스트 간선리스트
동적메모리 노드의 연결리스트
정점,간선
동적메모리 노드
인접 정보
포인터의 연결리스트
2D 포인터 배열
장점
동적 그래프에 사용 시 유리
단점
다수의 포인터 사용으로 복잡
배열
정점리스트 간선리스트
구조체 배열
정점,간선
구조체
인접 정보
첨자의 연결리스트
2D 첨자 배열
장점
다수의 포인터를 첨자로 대체하여 단순
단점
동적 그래프에 사용 시 불리
📢 그래프 구현 ADT
단순한화한 무방향그래프 ADT 구현
👉 Integer deg(v) : 정점 v의 차수를 반환 👉 Integer opposite(v,e) : 정점 v와 간선 e에 대한 반대쪽 끝점을 반환 👉 Boolean areAdjcent(v,u) : 정점 v와 u가 인접한지 여부를 반환 👉 Iterator adjacentVertex(v) : 정점 v의 인접정점을 모두 반환 👉 Iterator incidentEdge(v) : 정점 v의 부착간선을 모두 반환
A. 그래프가 인접리스트 구조로 표현된다.
B. 그래프가 인접행렬 구조로 표현된다.
전제
👉 인접행렬 구조에서 인접행렬은 배열 A에 저장됬다. 👉 index(v) 함수 사용 가능 : 인접행렬에서 정점 v에 대응하는 배열첨자를 반환
차수 메소드( deg(v) )
Alg deg(v) // 인접리스트 버전
input vertex v
output integer
c <- 0
e <- (v.incidentEdge).next
while(e != ∅)
c <- c + 1
e <- e.next
return c
// Total = O(deg(v))
======================================
Alg dev(v) // 인접행렬 버전
input adjacency matrix A, vertex v
output integer
c <- 0
vi <- index(v)
for j <- 0 to n-1
if(A[vi,j] != ∅)
c <- c + 1
return c
// Total = O(n)
나의 상대방 정점 반환 메소드( opposite(v,e) )
Alg opposite(v,e) // 인접리스트 버전
input vertex v, edge e
output vertex
u,w <- e.endpoints
if(v == u)
return w
else
return u
// Total = O(1)
==========================
Alg opposite(v,e) // 인접행렬 버전
input adjacency matrix A, vertex v, edge e
output vertex
u,w <- e.endpoints
if(v == u)
return w
else
return u
// Total = O(1)
정점 v,w가 인접한지 확인 메소드( areAdjacent(v,w) )
Alg areAdjacent(v,w) // 인접리스트 버전
input vertex v,w
output boolean
if(deg(v) < deg(w))
m <- v
else
m <- w
e <- (m.incidentEdges).next
while(e != ∅)
a,b <- e.endpoints
if((v == a) && (w == b) || (v == b) && (w == a))
return True
e <- e.next
return False
// Total = O(min(deg(v),deg(w)))
=====================================================
Alg areAdjacent(v,w) // 인접행렬 버전
input adjacency matrix A, vertex v,w
output integer
return A[index(v),index(w)] != ∅
// Total = O(1)
나의 인접한 정점 반환 메소드( adjacentVertex(v) )
Alg adjacentVertex(v) // 인접리스트 버전
input vertex v
output set of vertex objects
L <- empty list
e <- (v.incidentEdges).next
while(e != ∅)
L.addLast(opposite(v,e))
e <- e.next
return L.element()
// Total = O(deg(v)) // 자기랑 연결된 간선만 조사하면 되니깐
===================================
Alg adjacentVertex(v) // 인접행렬 버젼
input adjacency matrix A, vertex v
output set of vertex objects
L <- empty list
vi <- index(v)
for j <- 0 to n - 1
if(A[vi,j] != ∅)
L.addLast(opposite(v,A[vi,j]))
return L.element()
// Total = O(n) // 나를 제외한 모든 정점에 대해, 연결되어 있는지 하나씩 조사해야되니깐
나의 부착간선 반환 메소드( incidentEdges(v) )
Alg incidentEdges(v) // 인접리스트 버젼
input vertex v
output set of edge objects
L <- empty list
e <- (v.incidentEdges).next
while(e != ∅)
L.addLast(e)
e <- e.next
return L.element()
// Total = O(deg(v)) // 나한테 부착된 연결리스트만 확인하면 되니깐
=================================
Alg incidentEdges(v) // 인접행렬 버젼
input adjacency matrix A, vertex v
output set of edge objects
L <- empty list
vi <- index(v)
for j <- 0 to n - 1
if(A[vi,j] != ∅)
L.addLast(A[vi,j])
return L.elements()
// Total = O(n) // 나를 제외한 모든 정점에 대해 부착됬는지 확인해야되니깐
📢 번외
그래프 구현 방식 선택 : 다음 각 경우에 인접리스트 구조와 인접행렬 구조 둘 중 어느 것을 사용하겠는가 ?
👉 a. 그래프가 10,000개의 정점과 20,000개의 간선을 가지며, 가능한 최소한의 공간 사용이 중요 👉 b. 그래프가 10,000개의 정점과 20,000,000개의 간선을 가지며 가능한 최소한의 공간 사용이 중요 👉 c. 얼마의 공간을 사용하든, areAdjacent 질의에 가능한 빨리 답해야 할 경우
해결책
👉 a. 인접리스트 구조가 유리 = 실상 인접행렬 구조를 쓴다면 많은 공간을 낭비한다. 왜냐면 20,000개의 간선만이 존재하는데도 100,000,000개의 간선에 대한 공간을 할당하기때문 ( M <= (N(N-1)/2 ) 👉 b. 일반적으로, 이 경우에는 양쪽 구조 모두가 적합 = areAdjacent 작업은 인접행렬 구조가 유리, insertVertex와 removeVertex 작업에서는 인접리스트 구조가 유리 👉 c. 인접행렬 구조가 유리 = 이유는, 이 구조가 areAdjacent작업을 정점이나 간선의 개수에 관계없이 O(1)시간에 지원하기 때문이다.
O(log M) == O(log N)인 이유 ( M = 간선 수, N = 정점 수 )
👉 G를 N 개의 정점과 M 개의 간선으로 이뤄진 단순 연결그래프라 가정하자. 👉 M <= N(N-1)/2 이며, 이는 O(N^2)이다. 👉 따라서, O(log M) == O(log N^2) == O(2log N) == O(log N) 이다.
👉 키들을 외견상 무작위하게(Random) 분산시켜야 한다. 👉 계산이 빠르고 쉬워야 한다 ( 가능하면 상수시간 )
해시함수 예
📢 압축맵
나누기(Division) (보통사용 방식)
👉 h2(k) = |k| % M 👉 해시테이블의 크기 M은 일반적으로 소수(Prime)로 선택
승합제(MAD, Multiply Add and Divide)
👉 h2(k) = |ak + b| % M 👉 a와 b는 음이 아닌 정수로서, a % M != 0, 그렇지 않으면, 모든 정수가 동일한 값 b로 매핑됨
📢 해시코드맵
메모리 주소(Memory address)
👉 키 개체의 메모리 주소를 정수로 재해석( 모든 Java객체들의 기본 해시코드다. ) 👉 일반적으로 만족스러우나 수치 또는 문자열 키에는 적용 곤란
정수 캐스트(Integer case)
👉 키의 비트값을 정수로 재해석 👉 정수형에 할당된 비트 수를 초과하지 않는 길이의 키에는 적당 ( Java의 byte, short, int, float )
요소합(Component sum)
👉 키의 비트들을 고정길이(16 or 32bit)의 요소들로 분할한 후 각 ㅊ 합한다(overflow는 무시한다.) 👉 정수형에 할당된 비트 수 이상의 고정길이의 수치 키에 적당 ( 예 : Java의 long, double ) 👉 문자의 순서에 의미가 있는 문자열 키에는 부적당 ( 예: temp01-temp10, stop-tops-spot-pots )
다항 누적(Ploynomial accumulation)
👉 요소합과 마찬가지로, 키의 비트들을 고정길이(8,16,32bit)의 요소들로 분할 ( a(0),a(1),...,a(N-1) ) 👉 고정값 z를 사용하여 각 요소의 위치에 따른 별도 계산을 부과한 다항식 p(z)를 계산 (overflow 무시) 👉 p(z) = a(0) + a(1) * z + a(2) * z^2 + .... + a(N-1) * z ^ (N-1) 👉 문자열에 특히 적당 ( 예 : 고정값 z = 33을 선택할 경우, 50,000개의 영단어에 대해 단지 6회 충돌만 발생
📢 충돌해제 (중요 !!)
충돌(Collision) : 두 개 이상의 원소들이 동일한 셀로 매핑되는 것
즉, 상이한 키, k1과 k2에 대해 h(k1) = h(k2)면 "충돌이 일어났다."고 말한다.
분리연쇄법(Separate Chaining), 연쇄법 : 각 버켓 A[i]는 리스트 L(i)에 대한 참조를 저장 ( L(i)는 리스트 )
👉 해시함수가 버켓 A[i]로 매핑한 모든 항목들을 저장 👉 무순리스트가 또는 기록파일 방식을 사용하여 구현된 미니 사전이라 볼 수 있다.
장단점 : 단순하고 빠르다는 장점이 있으나 테이블 외부에 추가적인 저장공간을 요구
분리연쇄법(Separate Chaining)
예시
👉 h(k) = k % M 👉 키 : 25,13,16,15,7,28,31,20,1 ( = 충돌 일어난 키값 ) 👉 리스에 추가되는 항목들의 위치는, 리스트의 맨 앞에 삽입하는 것이 유리하다. (리스트의 tail 포인터 없는경우)
분할연쇄법 예시
📢 개방주소법 ( 선형조사법 )
개방주소법(Open Addresssing) : 충돌 항목을 테이블의 다른 셀에 저장
장단점 : 분리연쇄법에 비해 공간 사용을 절약하지만, 삭제가 어렵다는 것과 사전 항목들이 연이어 군집화
개방 주소법
선형조사법(Linear Probing) : 충돌 항목을 (원형으로)바로 다음의 비어있는 테이블 셀에 저장함으로써 충돌을 처리
즉, 다음 순서에 의해 버켓을 조사한다.
👉 A[ (h(k) + f(i)) % M ], f(i) = i, i = 0,1,2,...
검사되는 각 테이블 셀은 조사(Probe)라 불린다.
충돌 항목들은 군집화하며, 이후의 충돌에 의해 더욱 긴 조사열(Probe sequence)로 군집됨 = "1차 군집화"
예시
👉 h(k) = k % M 👉 키 : 25,13,16,15,7,28,31,20,1,38( = 충돌 키 )
선형조사법 예시
📢 개방 주소법( 2차 조사법 )
2차 조사법(Quadratic Probing) : 다음 순서에 의해 버켓을 조사
👉 A[ (h(k) + f(i) % M ], f(i) = i^2, i = 0,1,2,...
해시 값이 동일한 키들은 동일한 조사를 수반한다.
1차 군집화를 피하지만, 나름대로의 군집을 형성 할 수 있다. = "2차 군집화"
M이 소수가 아니거나 버켓 배열이 반 이상 차면, 비어 있는 버켓이 남아 있더라도 찾지 못할 수 있다. ( 단점 )
예시
👉 h(k) = k % M, f(i) = i^2 👉 키 : 25,13,16,15,7,28,31,20,1,38
2차 조사법 예시
📢 이중해싱
이중해싱(Double Hashing) : 두 번째의 해시함수 h`를 사용하여 다음 순서에 의해 버켓을 조사
👉 A[ (h(k) + f(i)) % M ], f(i) = i * h`(k), i = 0,1,2,....
동일한 해시값을 가지는 키들도 상이한 조사를 수반할 수 있기 때문에 군집화를 최소화한다.
h`는 계산 결과가 0이 되면 안된다. 👉 ( 0이 되면, f(i)는 결과적으로 0만 되겠죠 ? 그럼 한자만 계속 해싱충돌 )
최선의 결과를 위해, h`(k)와 M은서로소(Relative Prime)여야 한다.
👉 d(1)*M = d(2)*h`(k)이면, d(2) 개의 조사만 시도한다. 즉, 버켓들 중 d(2)/M만 검사 👉 h`(k) = q - (k % q) 또는 1 + (k % q)를 사용 ( 단, q < M은 소수며 M 역시 소수일 경우 ) 👉 한 마디로 위에 두 조건을 만족시키는, 해시함수를 적용하면, 군집화를 최소화하면서, 최소화로 실행가능
예시
👉 h(k) = k % M, h`(k) = 11 - (k % 11), ( 이때 q = 11이고, 11은 서로소이다. ) 👉 키 : 25,13,16,15,7,28,31,20,1,38( = 충돌 키 )
이중해싱 예시
개방주소법( 선형조사법, 2차조사법 ), 이중해싱 알고리즘
Alg findElement(k)
input bucket array A[0...M-1], hash function h, key k
output element with key k
v <- h(k) // h(k) = 해시함수는 보통 주어진다.
i <- 0
while(i < M)
b <- getNextBucket(v,i)
if(isEmpty(A[b])
return NoSuchKey
elseif(k == key(A[b])
return element(A[b])
else
i <- i + 1
return NoSuchKey
=========================================================
Alg insertItem(k,e)
v <- h(k)
i <- 0
while(i < M)
b <- getNextBucket(v,i)
if(isEmpty(A[b]))
Set bucket A[b] to (k,e)
return
else
i <- i + 1
overflowException()
return
Alg getNextBucket(v,i) // 선형조사법
return (v + i) % M
==========================================
Alg getNextBucket(v,i) // 2차조사법
return (v + i^2) % M
==========================================
Alg getNextBucket(v,i) // 이중해싱
return (v + i * h`(k)) % M
===========================================
Alg initBucketArray() // 버킷초기화(예시)
input bucket array A[0...M-1]
output bucket array A[0...M-1] initialized with null buckets
for i <- 0 to M-1
A[i].empty <- 1 // Set empty
return
===========================================
Alg isEmpty(b)
input bucket b
output boolean
return b.empty
📢 적재율
해시테이블의 적재율(Load factor), a = N/M ( N은 키 수, M은 버켓배열 크기 )
👉 즉, 좋은 해시함수를 사용할 경우의 각 버켓의 기대크기
적재율은 낮게 유지되어야 한다 ( 가능하면 1 아래로, 즉 a = N/M < 1 되도록)
좋은 해시함수가 주어졌다면, 탐색,삽입,삭제 각 작업의 기대 실행시간 = O(a)
분리연쇄법
👉 a > 1 이면, 작동은 하지만 비효울적 👉 a < 1 이면, O(a) = O(1)의 기대실행시간 성취 가능
개방주소법 ( 선형조사법, 2차조사법 )
👉 항상 a < 1 👉 a > 0.5 이면, 선형 및 2차 조사인 경우 군집화 가능성 농후하다. 👉 a <= 0.5 이면, O(a) = O(1) 기대실행시간
📢 해싱의 성능
해시테이블에 대한 탐색,삽입,삭제
👉 (최악의 경우)O(N) 시간 소요
최악의 경우란 : 사전에 삽입된 모든 키가 충돌할 경우
적재율(Load factor) : a = N/M은 해시테이블의 성능을 좌우한다.
해시값들은 흔히, 난수(Random numbers)와 같다고 가정하면, 개방주소법(선형조사법 or 2차조사법)에 의한 삽입을 위한 기대 조사횟수는 1/(1 - a)라고 알려져 있다.
외부노드(External Node, 리프노드(Leaf Node))에 다다르면, 찾는 Key가 발견되지 않은 것이다.
이진탐색트리 탐색( 목표 Key = 7 )
📢 이진탐색트리 삽입
우선 Key를 탐색한다.
Key가 현재 이진탐색트리에 존재하지 않을 경우 👉 탐색은 외부노드(w로 가정)에 도착
도착한 외부노드 w에 Key를 삽입한 후 👉 이 외부노드를 내부노드로 확장해줘야 한다.
여기서 외부노드 👉 Key값을 가지지 않은 트리의 말단에 위치한 노드 내부노드 👉 Key값을 가지고 있는 노드
Alg insertItem(K, E) // 이진탐색트리 삽입
input binary search tree T, Key K, element E
output none
w <- treeSearch(root(),K) // 일단, 이진탐색으로, K를 Key값으로하는 노드가 현재 있나 탐색
if(isInternal(w)) // 반환된 w노드가 내부노드 -> 이미 이진탐색트리 내에 존재한다는 것
return // 삽입 할 필요 X -> 종료
else // 외부노드인 경우
Set node w to (K, E) // w노드의 Key값을 K, 원소를 E로 적용하고
expandExternal(w) // ★ 이 w노드를 내부노드로 확장한다.
return
Alg expandExternal(z)
input external node z
output none
l <- getnode()
r <- getnode()
l.left <- Ø
l.right <- Ø
l.parent <- z
r.left <- Ø
r.right <- Ø
r.parent <- z
z.left <- l
z.right <- r
return
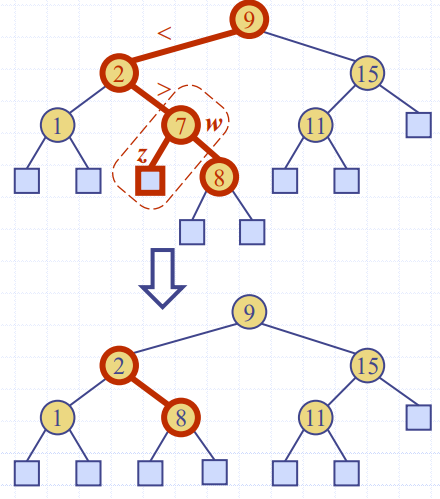
📢 이진탐색트리 삭제
크게 Case 1, Case 2로 나뉜다.
Case 1 👉 삭제할 Key를 가진 노드의 양쪽 자식 노드 중 하나가 외부노드일 경우 Case 2 👉 삭제할 Key를 가진 노드의 양쪽 자식 노드 둘 다 내부노드일 경우 ★
📌 이진탐색트리 삭제 ( Case 1. 삭제할 노드 양쪽 자식노드 중 하나가 외부노드인 경우 )
삭제할 노드의 양쪽 자식 노드 중 하나가 외부노드일 경우이다.
우선 삭제할 Key를 탐색
Key가 트리에 존재할 경우, 탐색은 Key를 저장하고 있는 노드(w라 가정)에 도착
노드 w의 자식 중 하나가 외부노드(z라 가정)라면, 노드 w의 축소과정을 통해, w, z를 트리로부터 삭제한다.
Case 1. 삭제( Key == 7 ) 삭제할 노드의 양쪽 자식노드 중 하나가 외부노드일 경우
📌 이진탐색트리 삭제 ( Case.2 삭제할 노드의 양쪽 자식노드가 둘 다 내부노드 일 경우 ) ★
삭제할 노드의 양쪽 자식노드 둘 다 내부노드일 경우이다. ( 이 때 삭제할 노드는 w라 가정 )
1. 트리 T에 대해 w의 중위순회 계승자 y와 그 자식노드 z를 찾아낸다.
노드 y는 우선 w의 오른쪽 자식으로 이동한 후, 거기서부터 왼쪽 자식들만을 끝까지 따라 내려가면 도달하게 되는 마지막 내부노드이며, 노드 z는 y의 왼쪽 자식인 외부노드
y는 T를 중위순회할 경우, 노드 w바로 다음에 방문하게 되는 내부노드이므로, w의 중위순회 계승자(Inorder successor)라 불린다.
따라서, y는 w의 오른쪽 부트리 내 노드 중 가장 왼쪽으로 돌출된 내부노드이다.
2. y의 내용을 w에 복사
3. reduceExternal(z) 작업을 사용해서 노드 y와 z를 삭제
Case 2. 삭제(Key == 2) 삭제할 노드 양쪽의 자식노드가 내부노드인 경우
Alg removeElement(K)
input binary search tree T, Key K
output element with Key K
W <- treeSearch(root(),K)
// Key K를 가지는 T내에 찾은 w노드가 외부노드인 경우
if(isExternal(W))
return NoSuchKey
// Key K를 가지는 T내에 찾은 W노드가 외부노드인 경우
e <- element(W)
z <- leftChild(W)
if(!(isExternal(z))
z <- rightChild(W)
if(isExternal(z)) // Case 1. 삭제할 W노드의, 양쪽 자식노드 중 하나가 외부노드인 경우
reduceExternal(z)
else // Case 2. 삭제할 W노드의, 양쪽 자식노드 둘 다 내부노드인 경우 ★
y <- inOrderSucc(W) // W의 중위순회계승자( 즉, W노드의 Key값 바로 다음으로 큰, Key값을 가진 노드 ), y
z <- leftChild(y) // 중위순회계승자 y노드의 왼쪽 자식노드가 z
Set node W to (Key(y),element(y)) // 삭제한다는 개념으로, 삭제할 W노드의 key값과 element값을 y의 Key,element로 변경
reduceExternal(z) // y에 대해, 내부노드 축소과정
return e
📢 이진탐색트리의 성능
높이 h의 이진탐색트리를 사용하여 구현된 N 항목의 사전을 가정해보자.
O(N) 공간을 사용한다.
탐색,삽입,삭제 작업 모두 O(h)시간에 수행
높이 h는
1. 최악의 경우 👉 O(N)
2. 최선의 경우 👉 O(log(N))
최악의 경우 = O(N)최선의 경우 = O(log(N))
📢 참고
동일한 키 집단으로 생성된 이진탐색트리에서, 삽입 순서와는 상관없이 항상 동일한 이진탐색트리가 생성된다 ?👉 NO !!
간단한 예로 확인가능 👉 [ 9,5,12,7,13 ] 순서와 [ 9,7,12,5,13 ] 순서로 생성되는 이진탐색트리의 모양은 다르다.
사전에 관한 주요 작업 1. 탐색(Searching) 2. 삽입(Inserting) 3. 삭제(Deleting)
사전에는 두 종류의 사전 존재한다. 1. 무순사전 ADT (Ex. "가계부") 👉 "순서가 없다" 2. 순서사전 ADT (Ex. "출석부", "백과사전") 👉 "학번 or 자음순,모음순" 등의 정렬된 순서가 있다.
사전 응용에는 두 가지 1. 직접 응용 👉 "연락처 목록", "신용카드 사용승인", "인터넷주소 매핑" 2. 간접 응용 👉 "알고리즘 수행을 위한 보조 데이터구조", "다른 데이터구조를 구성하는 요소"
📢 탐색
비공식적 : 탐색(Search)은 데이터 집단으로부터 특정한 정보를 추출함을 말한다.
공식적 : 탐색(Search)은 사전으로 구현된 데이터 집단으로부터 지정된 키(key)와 연관된 데이터 원소를 반환함을 말한다.
사전 구현에 따른 탐색 기법
구현 형태
구현 종류
예
주요 탐색 기법
리스트
무순사전 ADT
기록(log)파일
선형탐색
순서사전 ADT
일람표
이진탐색
트리
탐새트리
이진탐색트리 AVL 트리 스플레이 트리
트리탐색
헤시테이블
해싱
📢 무순사전 ADT
무순리스트를 사용하여 구현된 사전 👉 사전 항목들을 임의의 순서로 리스트에 저장 ( 이중연결리스트 또는 원형 배열을 사용 )
성능 삽입 : O(1) 소요 👉 새로운 항목을 기존 리스트의 맨 앞 또는 맨 뒤에 삽입하면 되기 때문 삭제 : O(N) 소요 👉 (최악의 경우)항목이 존재하지 않을경우, 리스트 전체를 순회해야 하기 때문 탐색 : O(N) 소요 👉 (최악의 경우)항목이 존재하지 않을경우, 리스트 전체를 순회해야 하기 때문
효과적인 경우 : 소규모 사전, or 삽입은 빈번하나, 탐색이나 삭제는 드문 사전 ( Ex. 서버의 로그인 기록 )
📢 무순사전 선형탐색 알고리즘
Alg findElement(K) // 배열 Ver.
input Array[0..N-1], Key K
output element with key K
i <- 0 // 첫번째 배열 인덱스 초기화
while(i < N) // 배열 끝까지 갈때까지 반복
if(A[i].key == K) // A[i].key != 목표 Key값
return A[i].key
else // A[i].key != 목표 Key값
i <- i + 1
return NoSuchKey
================================================================
Alg findElement(K) // 연결리스 Ver.
input doubly linked list with header H and trailer T, Key K
output element with Key K
i <- H.next // 연결리스트 Header에 다음 노드로 초기화
while(i != T) // 연결리스트의 끝 Tailer전까지
if(i.key == K) // i.key == 목표 Key값
return i.elem
else // i.key == 목표 Key값
i <- i.next
return NoSuchKey
📢 순서사전 ADT
순서리스트를 사용하여 구현된 사전 👉 사전 항목들을 배열에 기초한 리스트에 키로 정렬된 순서로 저장
성능 삽입 : O(N) 👉 새 항목을 삽입하기 위한 공간 확보를 위해, (최악의 경우) N개의 기존 항목을 이동해야 한다. 삭제 : O(N) 👉 항목이 삭제된 공간을 기존 항목들로 메꾸기 위해 (최악의 경우) N개의 기존 항목 이동해야 한다.탐색 : O(log(N)) 👉 이진탐색을 사용하면 가능하다.
효과적인 경우 : 소규모 사전, or 탐색이 빈번하나, 삽입 삭제는 드문 사전 ( Ex. 전화번호부 )
📢 이진탐색(Binary Search)
키값으로 된 "배열(Array)"에 기초한 리스트로 구현된 사전에 대해 탐색 작업을 수행한다.
배열의 키값들은 반드시 "정렬(Sorted)"되어 있어야 한다.
재귀적인 방식비재귀적 방식이 두 가지 모두 구현 가능하다.
입력크기(N)의 로그 수(log(N))에 해당하는 수의 재귀(or 비재귀)를 수행한 후 정지한다. ( Ex. 스무고개 )